AI 语音转文字(STT)工具深度对比(2026年版)
2026 年的语音转文字(STT)市场已经发生了翻天覆地的变化。从 OpenAI Whisper 的开源崛起,到 Deepgram、AssemblyAI 的商业 API 军备竞赛,再到 GPT-4o-transcribe 和微软 MAI-Transcribe-1 的入场——选择困难症已经成了开发者最头疼的问题之一。
这篇文章基于 Coval.ai、HuggingFace Open ASR Leaderboard、各厂商官方数据以及社区实测,对 2026 年主流 STT 工具进行全方位对比,帮你找到最适合的方案。
一、市场格局速览
全球 STT API 市场规模从 2024 年的 38 亿美元预计增长到 2030 年的 86 亿美元(CAGR 14.4%)。2026 年最显著的变化是:
- 精度天花板已接近人类水平:顶级模型在干净英语上的 WER(词错误率)已低至 3-5%,接近人类听写员水平
- 实时流式成为标配:Deepgram Flux 内置对话结束检测(<300ms),ElevenLabs Scribe v2 实现”负延迟”预测流式
- 开源模型经济持续下降:Groq 上的 Whisper-v3 每小时仅 $0.04,比 OpenAI 官方端点便宜 10-30 倍
- 多语言深度分化:从”支持 100 种语言”转向”支持 6 种语言但代码切换(code-switching)表现卓越”
二、关键指标解读
在对比之前,先理解几个核心指标:
| 指标 | 含义 | 好标准 |
|---|---|---|
| WER(词错误率) | (插入+删除+替换) / 总词数 | <5% 优秀,<10% 可用 |
| RTF(实时率) | 音频时长 / 处理时间 | >10x 可用,>100x 优秀 |
| 延迟(Latency) | 从音频输入到文本输出的时间 | 流式 <300ms 优秀 |
| 语种数 | 支持的语言数量 | 看质量而非数量 |
| 价格 | 通常按小时或分钟计费 | 考虑总拥有成本 |
⚠️ 重要提醒:厂商公布的 WER 数据通常基于”干净录音室音频”,实际生产环境中(噪音、口音、多人对话)表现可能差 2-3 倍。最可靠的方法是用你自己的生产音频做 A/B 测试。
三、开源模型对比
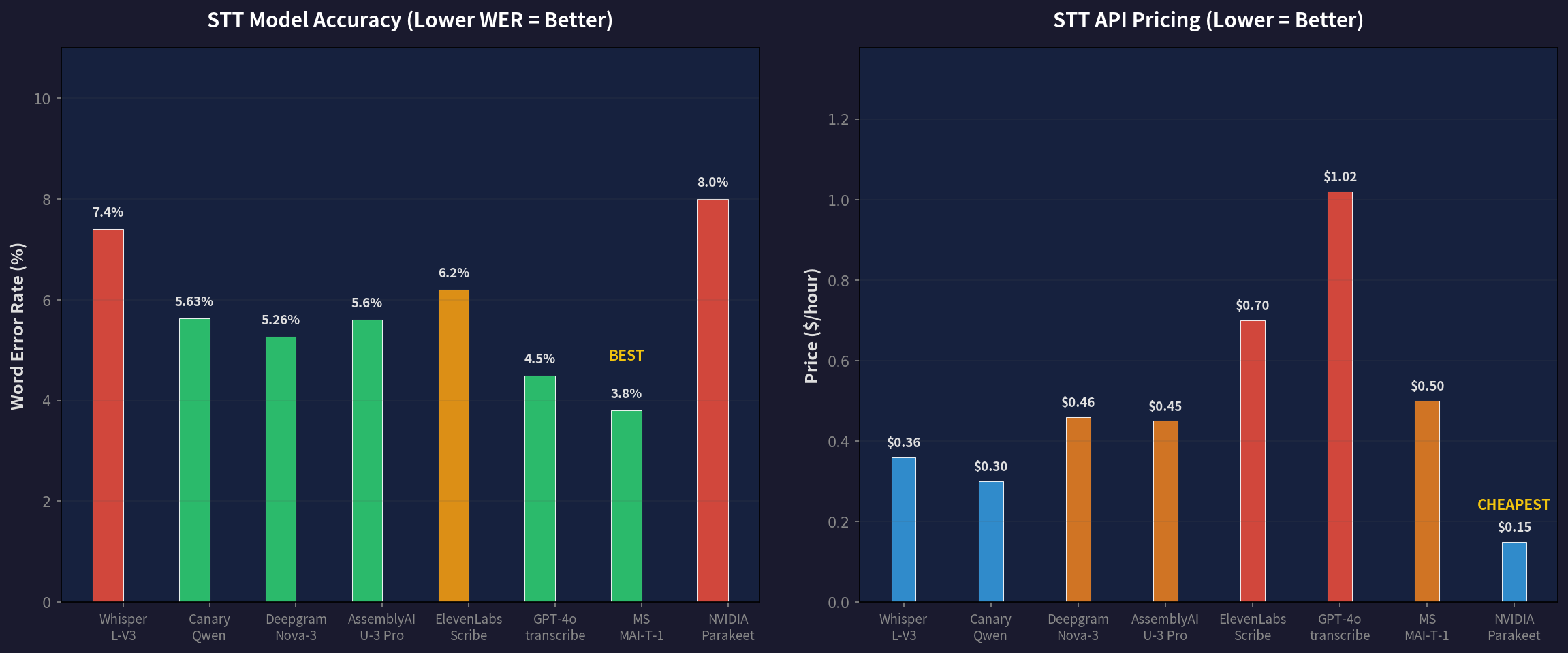
1. Canary Qwen 2.5B — 当前精度之王
- WER:5.63%(Open ASR Leaderboard),1.6%(LibriSpeech Clean)
- 架构:FastConformer 编码器 + Qwen3-1.7B LLM 解码器(SALM)
- 训练数据:23.4 万小时英语语音(YouTube、YODAS2、LibriLight 等)
- 噪音容忍:10dB SNR 下 WER 仅 2.41%
- 部署:需要 NVIDIA NeMo 工具链;建议对 >10s 音频做分块处理
- 许可证:CC-BY-4.0
- 适用场景:对精度要求极高的英语转录,如法律、医疗文档
2. Whisper Large V3 — 多语言标杆
- WER:7.4%(平均),高资源语言更优
- 语种:99+ 语言,零样本能力
- 训练数据:68 万小时多语言网络音频
- 架构:Transformer 编码器-解码器(32 层解码器)
- 许可证:MIT
- 适用场景:多语言转录,需要零样本语言检测的场景
3. Whisper Large V3 Turbo — 速度与精度平衡
- WER:7.75%(接近 Large V2 水平)
- 速度:比 Large V3 快 6 倍(Groq 上 RTF 达 216x)
- 参数量:809M(解码器从 32 层减到 4 层)
- VRAM:约 6GB
- 缺点:翻译性能下降(被排除在微调之外)
- 适用场景:多语言转录且速度优先
4. Distil-Whisper — 蒸馏效率
- WER:与 Large V3 差距 <1%
- 速度:比 Large V3 快约 6 倍
- 参数量:756M(编码器来自 Large V3,2 层解码器)
- 优势:重复短语更少,插入错误率低 2.1%
- 限制:仅支持英语(多语言请用 Whisper Turbo)
- 适用场景:英语转录且需要高效率
5. NVIDIA Parakeet TDT — 超低延迟流式
- WER:约 8.0%
- RTF:>2,000x(Open ASR 最快)
- 架构:RNN-Transducer(流式最优架构)
- 参数量:1.1B
- 训练数据:6.5 万小时多样化英语音频
- 适用场景:实时字幕、电话系统、需要极低延迟的场景
6. IBM Granite Speech 3.3 8B — 企业级精度
- WER:约 5.85%(Open ASR)
- 语种:英语、法语、德语、西班牙语;支持英→日、英→中文翻译
- 噪音韧性:从干净到噪音仅 7.54% 性能下降
- 许可证:Apache 2.0
- 适用场景:企业级多语言转录+翻译
四、商业 API 对比
1. Deepgram Nova-3 + Flux
- WER:5.26%(批处理)
- 延迟:流式 <300ms
- Flux 特色:内置对话结束检测(EOT),中位数 <300ms,节省 200-600ms 代理响应时间
- 语种:Nova-3 支持 30+ 语言;Flux 支持 10 种语言+代码切换
- 定价:流式 $0.0048-0.0078/分钟;语音代理 API $0.075/分钟
- 适用场景:语音代理、呼叫中心、需要低延迟+高准确的场景
2. AssemblyAI Universal-3 Pro
- WER:5.6%
- 特色:引入”语音语言模型”,支持自然语言关键词提示(最多 1,500 词)
- 语种:U-3 Pro 支持 6 种语言+代码切换;U-2 支持 99 种语言
- 定价:异步 $0.21/小时;流式 $0.45/小时
- 适用场景:需要 NLU + 转录一体化的应用
3. OpenAI GPT-4o-transcribe
- WER:约 4.5%(社区实测最佳)
- 特色:基于 GPT-4o 的转录能力,对技术术语、口音、噪音有出色表现
- 语种:50+ 语言
- 定价:$0.006/分钟($0.36/小时)
- 缺点:无原生实时流式(需单独使用 Realtime API),25MB 文件大小限制
- 适用场景:综合精度要求最高的场景
4. GPT-Realtime-Whisper(2026 年 5 月发布)
- 定价:流式 $0.017/分钟
- 特色:OpenAI 首次将流式优化 STT 与批处理 Whisper 分离
- 适用场景:需要 OpenAI 生态内实时转录
5. ElevenLabs Scribe v2 Realtime
- 延迟:亚 150ms
- 语种:90+ 语言
- 特色:”负延迟”预测流式(在说话者说完之前就开始输出)
- 定价:约 $0.70/小时
- 适用场景:对延迟极度敏感的实时应用
6. Microsoft MAI-Transcribe-1(2026 年 4 月发布)
- WER:3.8%(FLEURS 25 语言平均)
- 特色:微软首个自研 STT 模型,击败 Whisper Large v3 在所有 25 种语言上
- GPU 成本:比竞品低约 50%
- 定价:约 $0.50/小时
- 适用场景:Azure 生态用户,多语言高精度需求
7. Gladia Solaria-1
- WER:比竞品低 29%(Gladia 公开基准测试)
- 语种:100+ 语言,包含 42 种其他 API 不支持的语言(孟加拉语、旁遮普语、他加禄语等)
- 说话人分离:捆绑在基础价格中(pyannoteAI Precision-2)
- 定价:异步 $0.20-0.61/小时;实时 $0.25-0.75/小时
- 适用场景:多语言、嘈杂环境、多人对话转录
8. 其他值得关注的选项
| 工具 | 特色 | 定价 |
|---|---|---|
| Google Cloud Speech-to-Text (Chirp 3) | 100+ 语言,专业模型(医疗/电话) | $0.006/15秒起 |
| Amazon Transcribe | AWS 生态集成,呼叫分析 | $0.024/分钟 |
| Speechmatics Ursa 2 | 口音/方言处理领先,代码切换比竞品好 35% | 企业定价 |
| Krisp VIVA 2.0 | 语音隔离层,噪音环境下 WER 降低 10-30% | 按量计费 |
五、选型决策指南
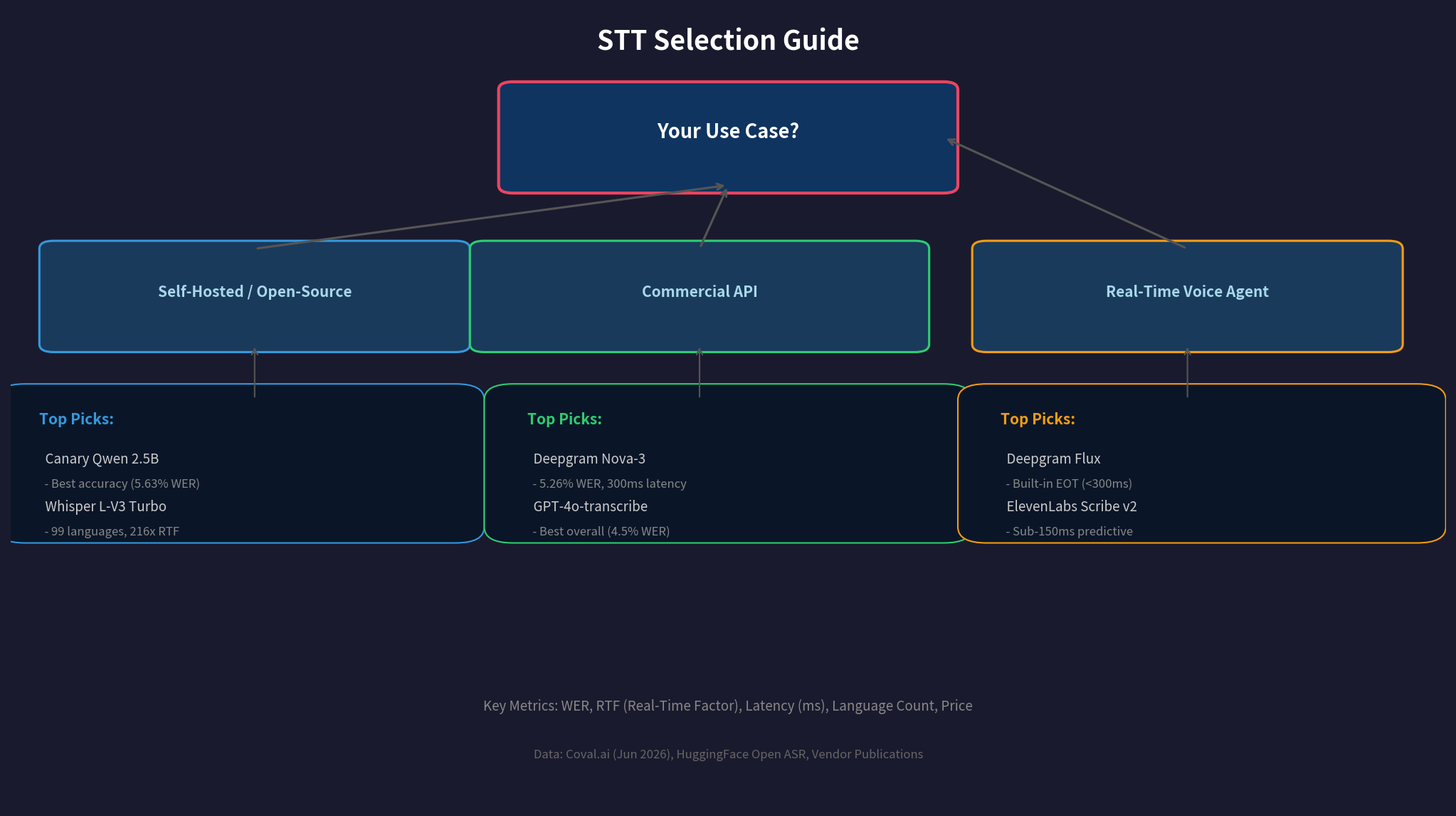
场景 A:自托管 / 开源优先
- 精度第一 → Canary Qwen 2.5B(英语)或 Whisper Large V3(多语言)
- 速度第一 → Whisper Large V3 Turbo 或 Distil-Whisper
- 超低延迟 → NVIDIA Parakeet TDT
- 边缘部署 → Moonshine(27M 参数,可在手机运行)
场景 B:商业 API 优先
- 综合最佳 → GPT-4o-transcribe(4.5% WER)
- 性价比 → Deepgram Nova-3(5.26% WER,$0.46/小时)
- 多语言深度 → Gladia Solaria-1(100+ 语言,含小众语言)
- Azure 生态 → Microsoft MAI-Transcribe-1
场景 C:实时语音代理
- 首选 → Deepgram Flux(内置对话结束检测,<300ms)
- 备选 → ElevenLabs Scribe v2(亚 150ms 预测流式)
- OpenAI 生态 → GPT-Realtime-Whisper
六、2026 年值得关注的趋势
- 对话式语音识别(Conversational Speech Recognition):从单纯的”听写”转向理解对话上下文、处理打断和交叉对话
- LLM 增强转录:用大语言模型后处理转录结果,修正专业术语、统一格式、提取实体
- 端侧部署:随着模型压缩技术进步,STT 正在从云端走向设备端(隐私、延迟、成本三重优势)
- 多模态融合:STT + 视觉(唇读辅助)+ 上下文理解的融合方案正在兴起
七、总结
2026 年的 STT 市场已经非常成熟,顶级模型在干净英语上的 WER 已接近人类水平。选择的关键不再是”哪个最准确”,而是”哪个最适合你的场景”:
- 精度为王 → GPT-4o-transcribe 或 Canary Qwen 2.5B
- 速度为王 → Whisper Turbo 或 Parakeet TDT
- 实时代理 → Deepgram Flux 或 ElevenLabs Scribe v2
- 多语言深度 → Gladia Solaria-1 或 Whisper Large V3
- 自托管省钱 → Whisper 系列(Groq 部署每小时仅 $0.04)
最重要的是:用你自己的生产音频做 A/B 测试。厂商基准测试无法替代真实场景验证。
数据来源:Coval.ai (2026.06), HuggingFace Open ASR Leaderboard, Deepgram, AssemblyAI, OpenAI, Microsoft, ElevenLabs, Gladia 官方发布。所有数据截至 2026 年 6 月,价格可能随时间变化。