分析日期:2026-05-28
涉及项目:Hermes Agent
一、Hermes 当前音频处理架构
1.1 音频摄入流程
1
| 用户音频 → gateway 捕获 → Whisper STT → 文字 → LLM
|
关键发现:
- ❌ 没有音频 native 路径:代码中不存在类似图片的
pending_native_audio_paths
- ❌ 音频文件被丢弃:STT 完成后,原始音频文件不被传递给 LLM
- ✅ 图片有 native 路径:图片通过 base64 编码为
image_url content part 直接传给模型
1.2 音频输出流程
1
| LLM 文字回复 → TTS 引擎 → 音频文件 → 平台发送
|
TTS 配置:
- 引擎:Edge TTS
- 语音:
zh-CN-XiaoxiaoNeural(微软晓晓,中文女声)
1.3 图片 vs 音频架构对比
| 维度 |
图片 |
音频 |
| Native 路径 |
✅ 存在 |
❌ 不存在 |
| 模型收到 |
文字 + 图片像素 |
仅文字 |
| 中间层 |
无 |
Whisper STT |
二、三种语音聊天方案对比
方案 A:当前架构(Whisper + LLM + TTS)
1
| 音频 → Whisper(STT) → 文字 → LLM → 文字 → TTS → 音频
|
| 特征 |
说明 |
| 延迟 |
~3-5 秒 |
| 模型感知 |
❌ 只收到文字,无法感知语调/情绪 |
| 改动量 |
无(已实现) |
1
| 音频 → GPT-4o(端到端) → 文字 → TTS → 音频
|
| 特征 |
说明 |
| 延迟 |
~1-2 秒 |
| 模型感知 |
✅ 能感知语调/情绪 |
| 改动量 |
中等 |
方案 C:Realtime API(双向音频流)
1
2
| WebSocket 长连接
音频流 ←→ 模型 ←→ 音频流
|
| 特征 |
说明 |
| 延迟 |
~0.3-0.8 秒 |
| 模型感知 |
✅ 端到端音频理解 |
| 改动量 |
大 |
参考项目:BridgeSpeak — 跨 agent skill,基于 OpenAI gpt-realtime-2,约 280 行 Python WebSocket 客户端。
三、方案对比总结
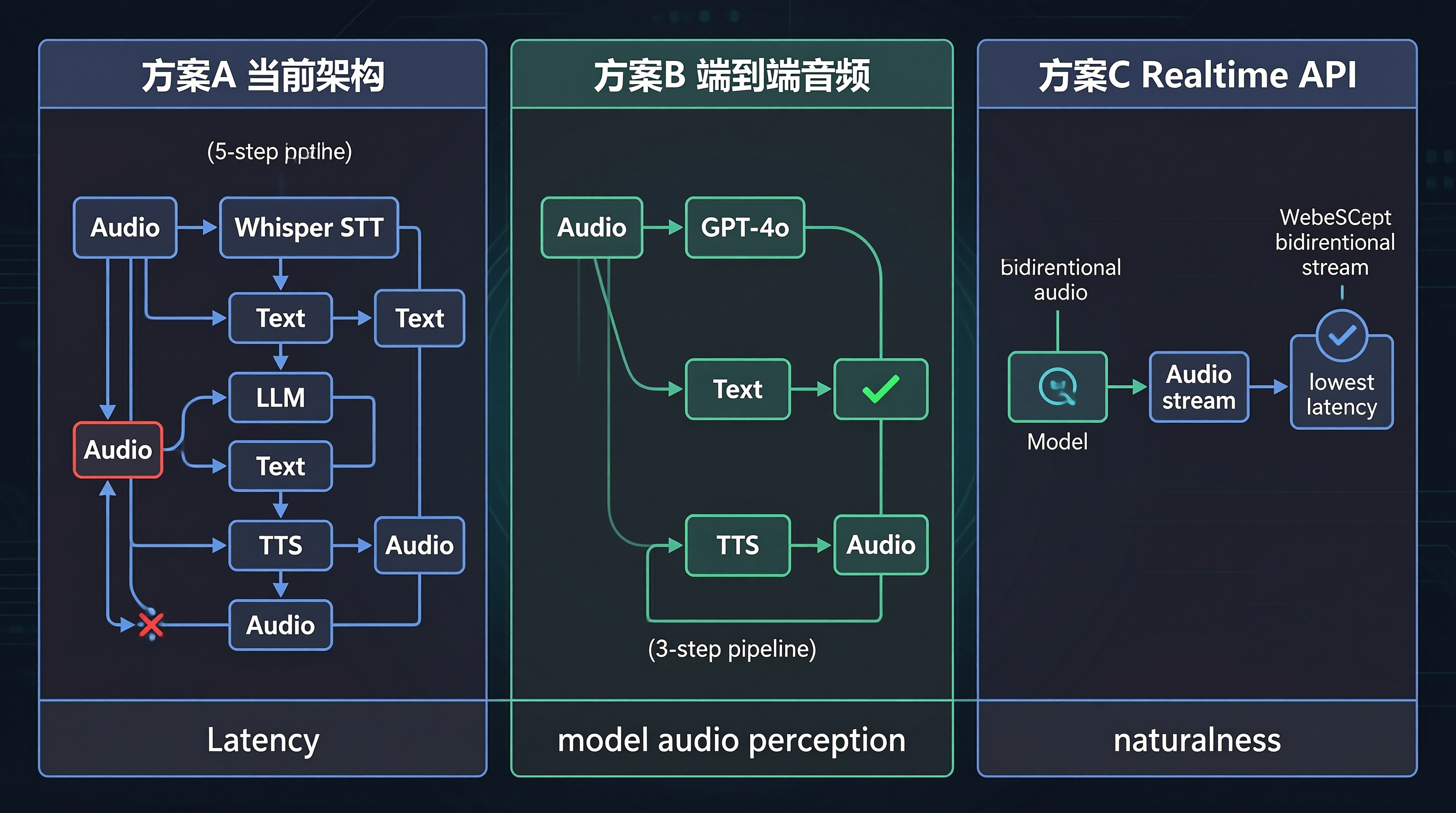
| 维度 |
方案 A(当前) |
方案 B(GPT-4o REST) |
方案 C(Realtime API) |
| 架构 |
两步走(STT→LLM) |
一步走(端到端) |
WebSocket 双向流 |
| 延迟 |
~3-5s |
~1-2s |
~0.3-0.8s |
| 模型感知音频 |
❌ |
✅ |
✅ |
| 改动量 |
无 |
中等 |
大 |
| 流式 |
❌ |
❌ |
✅ |
| 自然对话感 |
低 |
中 |
高 |
四、SenseNova-U1-Fast 与 Realtime API 的关系
澄清:SenseNova-U1-Fast 和 Realtime API 没有直接关系。
| 概念 |
说明 |
| SenseNova-U1-Fast |
商汤的一个模型(推理速度快) |
| Realtime API |
OpenAI 的一个WebSocket 端点(/v1/realtime) |
| 关系 |
两者是不同厂商的不同技术 |
五、推荐路径
| 目标 |
推荐方案 |
| 快速验证模型能否感知音频 |
方案 B(GPT-4o audio input) |
| 最佳体验(低延迟、自然对话) |
方案 C(Realtime API) |
| 保持当前架构、仅优化 STT |
设置 Whisper language: "zh" 提升中文识别率 |
六、代码参考位置
| 文件 |
内容 |
~/.hermes/config.yaml |
STT/TTS 配置 |
run.py L13402-13480 |
_enrich_message_with_transcription() — STT 转录 |
run.py L6870-6960 |
_prepare_inbound_event_text() — 音频捕获 |
agent/image_routing.py |
build_native_content_parts() — 图片 base64 编码参考 |
七、扩展方向
- 实现音频 native 路径:参考图片的
pending_native_image_paths,添加 pending_native_audio_paths
- 切换模型提供商:在
config.yaml 修改 agent.provider 和 agent.model
- 集成 BridgeSpeak:将 BridgeSpeak skill 复制到
~/.hermes/skills/voice/bridgespeak/
- 优化 Whisper 中文识别:在
config.yaml 设置 stt.language: "zh"
本文基于 Hermes Agent 代码分析生成,2026-05-28